When we began work on the new Status page of YippieMove ’09 we searched high and low for good charting software, both server based and dynamic. OFC 2 came out on top. OFC is an excellent Flash charts program written primarily by John Glazebrook. It supports several different chart types including line graphs, bar graphs and pie charts. It dynamically reads its data using JSON.
To meet WireLoad’s specific design goals for YippieMove’s status page a number of modifications were made. We needed a particular look and feel, we wanted the fastest possible load times and there were a couple of glitches when using our particular data sets that needed fixing. Since many of these changes were very specific to our use case we opted to just branch the software and not disturb the ordinary development of OFC. This branch is what we are releasing today as OFC WireLoad Edition 0.2. We hope it will benefit the OFC community and perhaps interested parties will be able to find pieces and parts they can use elsewhere.
OFC 2 Hyperion was used as the base. An overview of the changes can be found below.
Visual Changes
- Support for a gradient background.
- Chart encompassing border.
- Look of axises changed.
- Pie chart drop shadow.
- “Fuzzy” grid lines sharpened up.
- New ‘spinner’ progress indicator.

Functional Changes
- Fast loading progress indicator which starts showing before the whole flash file has downloaded and remains until the graph data has been loaded.
- New on the side legend for pie charts.
- New build script for building without the Windows specific Flash Develop.
Size Reduction
- Each chart type can be enabled or disabled at build time, which enables a site specific light-weight build. Many individual functions such as image saving can similarly be disabled.
- Embedded fonts are no longer required for 0-90 degree rotated X axis labels or rotated Y axis labels.
- Reduction of some redundant code.
The final version used on YippieMove’s status page is about 50KiB, down from 200KiB in the original.
If you want to set OFC WireLoad Edition 0.2 up for a test, be aware that when using IE7, SWFObject did not always properly detect the running Flash version in our testing. So you may see unexpected degradation to your non Flash content. Updating to the latest version of Flash seems to resolve the issue, regardless of your installed version – it’s the reinstalling itself that fixes the problem. Word on the net is that there is an installation corruption issue happening to some IE7 users.
Downloads and a complete change log can be found on WireLoad’s open source page.
]]>Since our system is pretty straight forward (Postfix + DBmail), our conclusion was that it was the graylisting that caused us trouble. We took a fresh look on the market and realized that SpamAssassin probably was the best way to go. Thanks to FreeBSD’s ports, we were able to replace Postgray with SpamAssassin in less than an hour.
This morning when I woke up, I took a look at the maillogs. SpamAssassin seems to be doing it’s job pretty well, as it caught a bunch of SPAM. Bye Bye Postgrey. Welcome SpamAssassin.
]]>Over the course of the last few years, I’ve been in charge of putting up a number of websites for various companies, often as favors for friends. In most cases, I’ve ended up using one out of two solutions: Joomla! and WordPress. While both of these projects have evolved greatly over the last few years, they are vastly different. Joomla! has always been intended as a ‘fit-all-your-possible-needs’-kind of CMS solution, while WordPress was developed as a blog with CMS capabilities. Recently WordPress has opened up to allow its users to set up a site with static-only material (with the option of a blog-page), without having to hack the code. Hence it’s one step closer to being a direct competitor to Joomla!.
 |
 |
I will probably step on a few peoples feelings here, but I will argue that Joomla! is an example of a poorly managed open source project and that WordPress is a very successfully managed one. Certainly I don’t mean that Joomla! is a useless piece of junk, but that the lead developers have quite a bit to learn from WordPress. The main thing that Joomla! is vastly behind on is usability. While it is true that Joomla! 1.5 is a step in the right direction, it is still light years behind WordPress. Let me illustrate with two examples of common tasks.
Example 1: Create a blog-post with an image
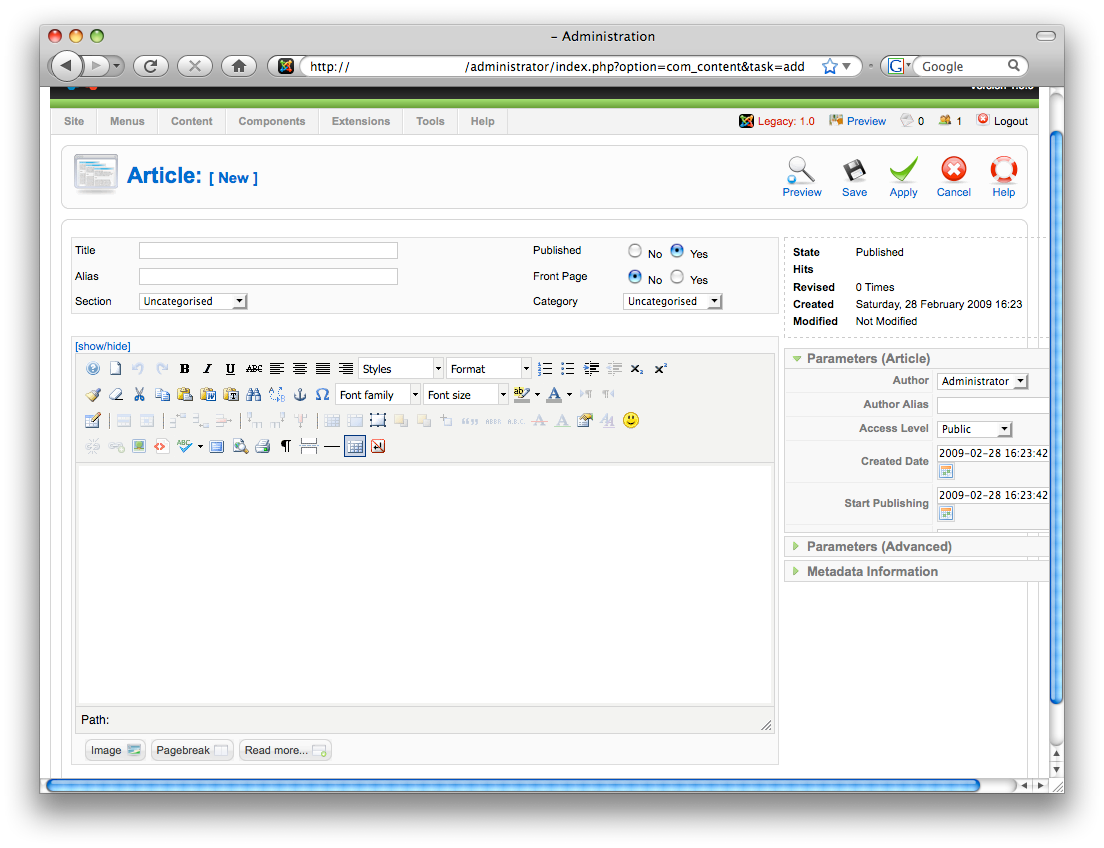
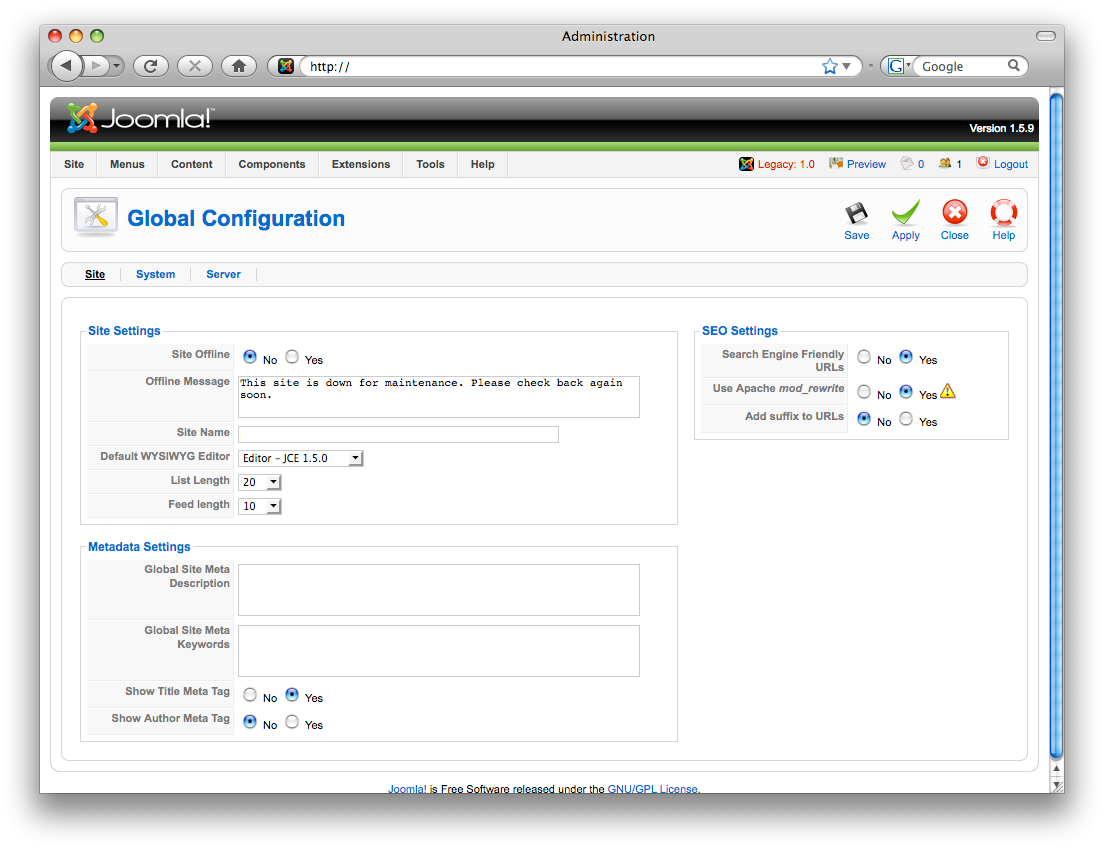
Joomla!
- From the ‘Control Panel,’ click ‘Add New Article.’
- There are two image buttons. If you use the wrong one, you won’t be able to upload an image (as you will only browse the existing images). You must use the one below the text field.
- Select a ‘Title,’ the right ‘Section’, and then the right ‘Category.’
- Write the content and save.
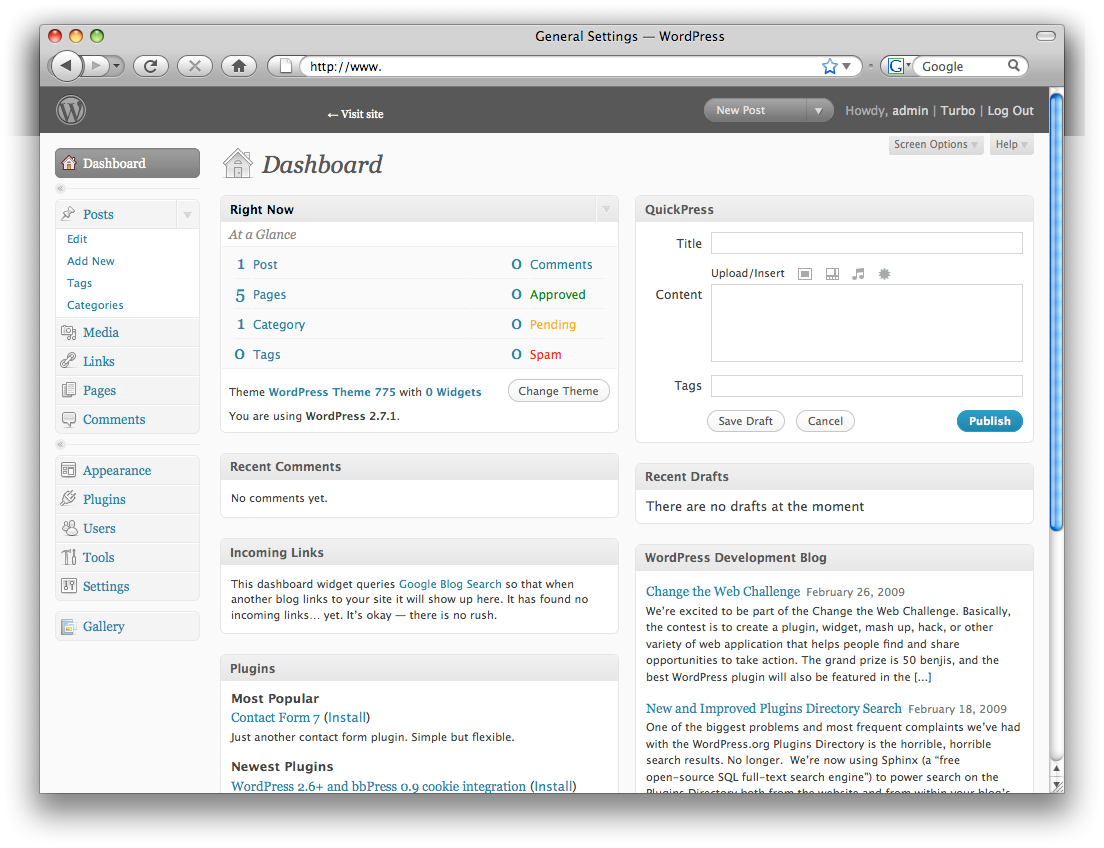
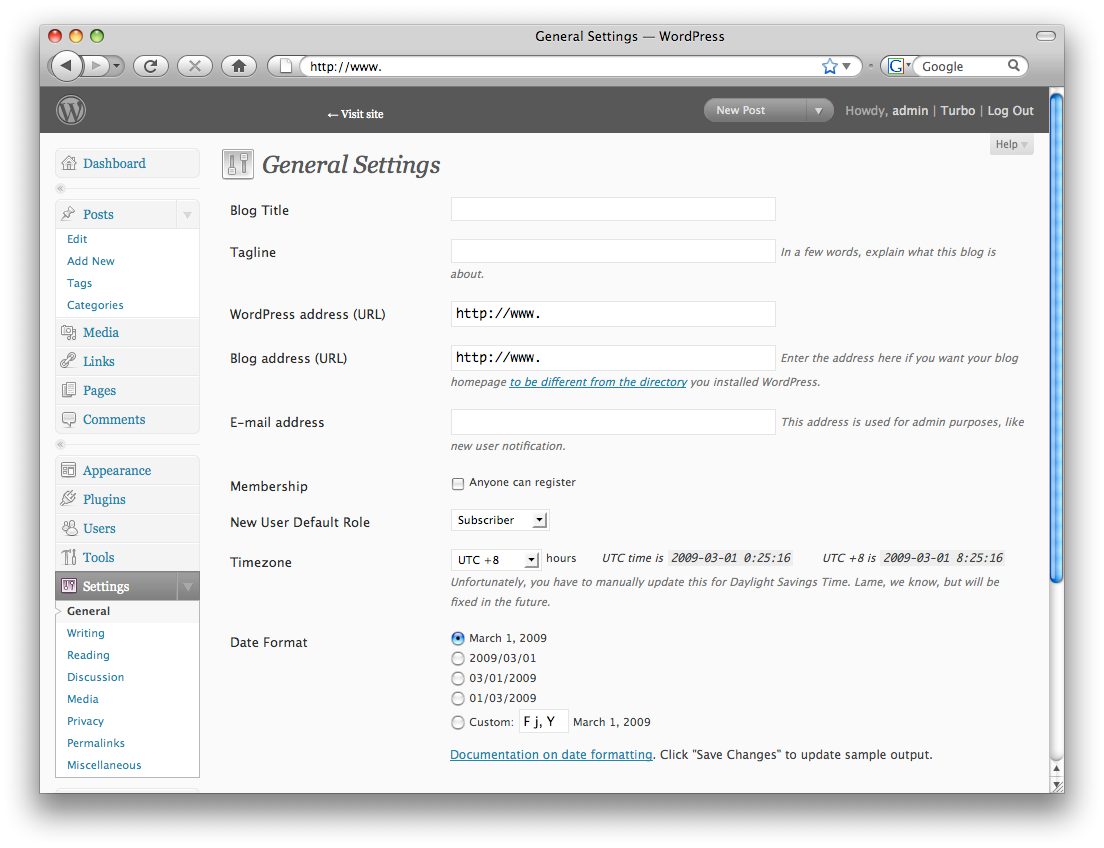
WordPress
- Select QuickPress in the Dashboard.
- Click on the image icon and upload the image.
- Select title, write your content and press publish.
 |
|
Example 2: Create a static page accessible from the menu
Joomla!
- From the ‘Control Panel,’ click ‘Add New Article.’
- Select a ‘Title,’ the right ‘Section’, and then the right ‘Category.’
- Write the content and save it.
- From the top-menu, select ‘Menu’ and ‘Main Menu’ (assuming you want to add it to the main menu.)
- Click ‘New.’
- Select ‘Internal link,’ and ‘Articles,’ and then finally ‘Article Layout.’
- Fill in the title of the object as well as the parent item.
- In the column to the right, you now need to browse your list of articles and select the desired article.
- Press ‘Save.’
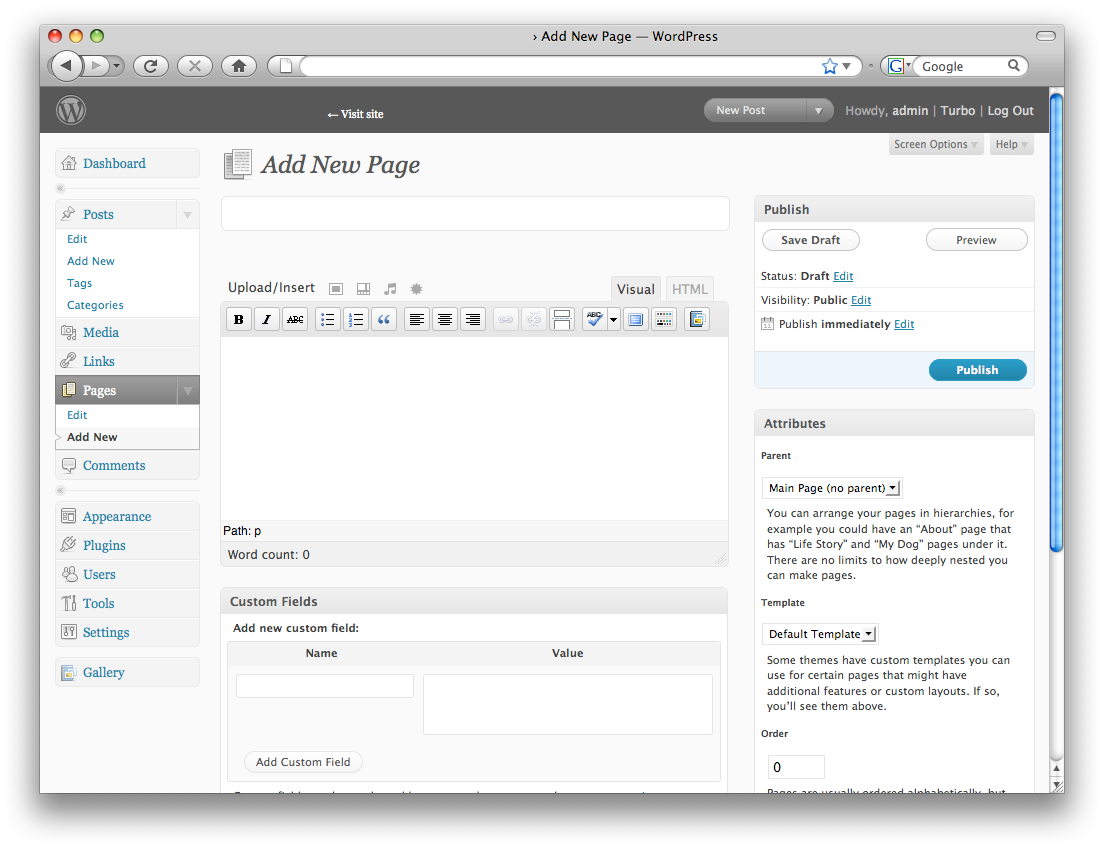
WordPress
- From the Dashboard, click ‘Pages.’
- Select ‘Add New.’
- Fill in the title and contents.
- Select the parent item (if other than root.)
- Click ‘Publish.’
|
 |
Let’s step back for a minute and imagine the following scenario: you’re in charge of putting up a website for a company. They might want to put up about 10 or so pages with various information. According to my experience this is a pretty common situation. You can do this with either Joomla! or WordPress – both are fully capable of delivering this. Assuming you’re going to buy a template to solve the design issue, it will probably take you about an hour with either of the software to get to the first draft (assuming you’ve been working with them in the past.) So far so good. This is where they start to differ. With WordPress you’re pretty much done by now. However, with Joomla!, you’ll probably have to spend another hour or two just trying to re-organize the different modules to fit the template you bought (in many cases, just to get the basics to work.) Next you will end up spending even more time trying to figure out how to re-organize the different menus. You need to link up a particular document to a particular menu-entry (as illustrated above.) If you want a blog-feed, you need to set up a dedicated section or category (I still don’t really know the difference between the two.) Moreover, you need to select the ‘style’ of blog you want.
 |
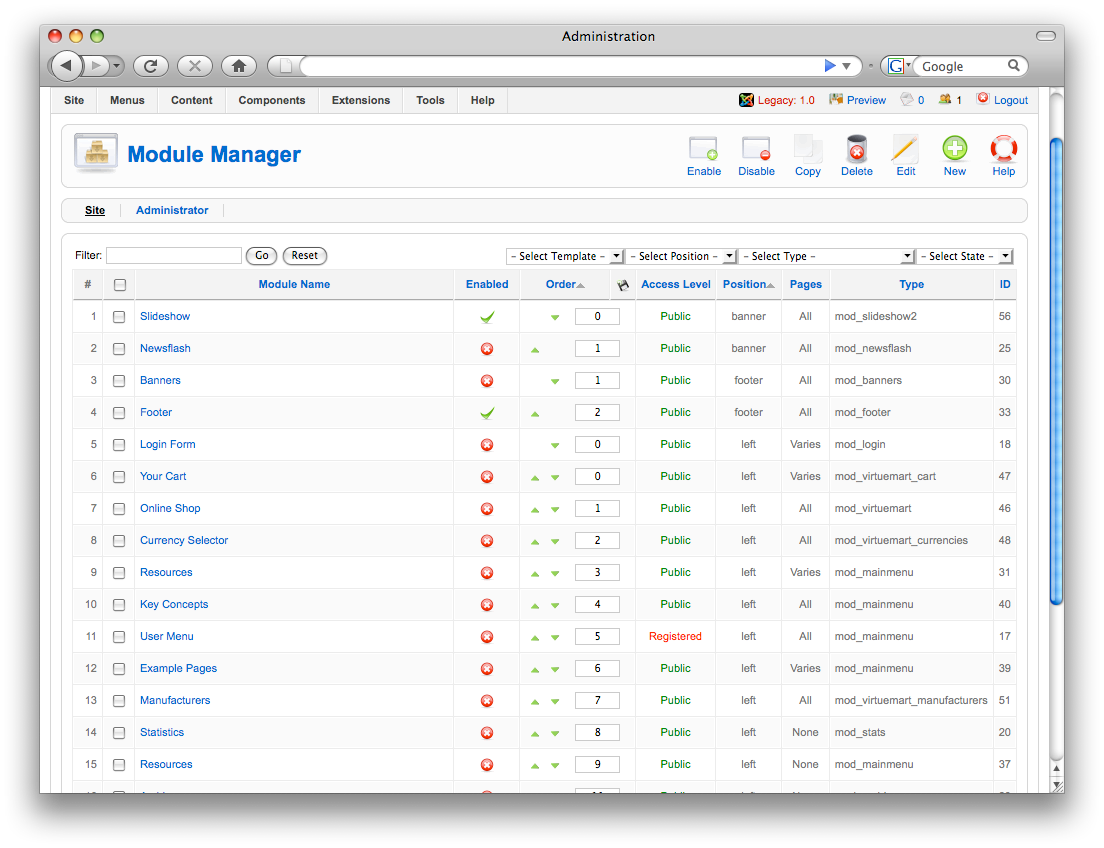 |
in Joomla! |
Let’s say you managed to figure all of that out and that you got the site ready. Now it’s time to hand over the site to the customer. There will obviously be some training involved, and here’s another crucial difference between Joomla! and WordPress. Training someone to learn WordPress takes (in my experience) less than 30 minutes, and they truly understand it. Training someone to use Joomla! takes at least an hour, and they still don’t really understand it.
Again, I’m not saying that Joomla! is useless, it’s that WordPress is a more intuitive piece of software. Let me throw an analogy out there that will probably help you better understand my point. If Joomla! is Linux, then WordPress is Mac OS X. WordPress might offer only 90% of the features of Joomla!, but in most cases WordPress is both easier to use and faster to get up and running. I use and love Linux, it just doesn’t have that elegant touch to Mac OS X does.
To Joomla!’s defense, there are at least two scenarios I can think of where Joomla! is a better fit than WordPress. The first one would be eCommerce. If you install VirtueMart on Joomla! you can be up running with an eCommerce site pretty quickly. However, the problem is that it does not feel like it is a part of Joomla!, but rather as a 3rd party module that works in Joomla! (which is pretty much what it is.) The second one would be a site where you need to have multiple levels of permissions (ie. an extranet). WordPress only offers three levels of permission (public, private, and password protected), while Joomla! is much more flexible.
 |
 |
in Joomla! |
in WordPress |
Joomla! is not doomed. It just has a long way to go when it comes to usability. WordPress has really been developed by the KISS-principle, while Joomla! appears to have been developed to solve every problem on Earth (by engineers, for engineers). Going back to the two problems I mentioned above, where Joomla! beats WordPress. I think it would actually be less of a challenge to add support for eCommerce and more permission levels to WordPress, than it would be to improve the usability in Joomla! to reach WordPress’ level.
Just as a side note, a quick line-count on the latest versions of both software reveals that Joomla 1.5.9 has 350,975 lines of codes, while WordPress 2.7.1 has a mere 159,682 (might not be completely accurate, but that’s what ‘wc -l’ said). Hence, even if WordPress only offers 70% of the features of Joomla!, which I am pretty sure it does, their code is written much more efficiently.
]]>This is the intial version 0.1. The next version is already in the works, and we will be releasing it as soon as we think it is ready for the spotlight.
]]>While the setup we described in these article worked out great, there were a few things that we didn’t really like about the setup:
- We connected with SSH from the Cacti server to the server we wanted to monitor (security issue).
- We were using regular SSH tunnels. While these are great, they do have a tendency to die (reliability issue).
- Due to security and portability, we wanted to isolate Cacti to a separate server (or VM).
1. Turning the tunneling around
The reason why we didn’t like to have the Cacti server connecting to the servers was simply that we needed one more user account on the remote servers. If these are production servers, it’s desirable to keep the publicly accessible user accounts to a minimum.
As it turned out, replacing the ‘-L’ with a ‘-R’ in the tunneling command turns the tunnel around. Instead of opening a port on the local machine, it opens a forwarded port on the remote server. By doing this, we can connect from the remote server to the Cacti server and still fulfilling the same purpose (but without creating an additional user on the remote server).
2. Creating more reliable tunnels
One of the major problems we were having with the setup was that the tunnels died for one reason or another. We initially solved this by writing a bash-loop that automatically reloaded the tunnel if that occurred. However, we were still experiencing some problems with dead tunnels.
The solution to the problem was autossh, a simple front-end to SSH that keeps the tunnel alive.
With autossh, we could simply launch the tunnels at boot-time on the remote server (in rc.local) without having to worrying about them dying. As we were implementing this on a number of servers, we wrote a small bash-script that launches autossh with the server-specific settings. The script looks like this:
#!/bin/sh
REMOTEPORT=2001
MONITORPORT=29001
/usr/bin/autossh -M $MONITORPORT -q -f -N -R
127.0.0.1:$REMOTEPORT:127.0.0.1:161 [email protected]
This script creates a tunnel on port 2001 ($REMOTEPORT) on the Cacti host (cacti.server.tld) that goes to port 161 on the local machine (in this case, the server we want to monitor).
Isolate Cacti
In order to make our monitoring both more secure and portable, we felt that we wanted to isolate the monitoring to a separate Virtual Machine. This was easily done by creating a new VM under VMware Server. If you’re lazy, there are ready-to-use VMware images to download on the Cacti forum.
Bonus: Monitor several hosts with one tunnel
While reading the Cacti forum the other day, I ran across this article that talks about SNMP Proxies. By adding an extra entry in the SNMP config file, it’s possible for a single host to relay SNMP information about the other hosts on the network. This is very useful if you’re trying to monitor more than one host on the same network, as you don’t need one tunnel per server (beware that this creates a single-point-of-failure though).
Conclusion
After implementing these changes, we feel much more comfortable with our Cacti setup. Not only is it more reliable with more robust tunnels, but it’s also more secure.
The next Cacti-related task we will be looking at is to design custom plug-ins to monitor our own apps.
]]>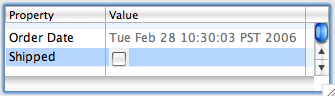
An unsightly gray checkbox background.
I came up with this hack to hack the hack to work.
private Image makeShot(Control control, boolean type) { // Hopefully no platform uses exactly this color // because we'll make it transparent in the image. Color greenScreen = new Color(control.getDisplay(), 222, 223, 224); Shell shell = new Shell(control.getShell(), SWT.NO_TRIM); // otherwise we have a default gray color shell.setBackground(greenScreen); Button button = new Button(shell, SWT.CHECK); button.setBackground(greenScreen); button.setSelection(type); // otherwise an image is located in a corner button.setLocation(1, 1); Point bsize = button.computeSize(SWT.DEFAULT, SWT.DEFAULT); // otherwise an image is stretched by width bsize.x = Math.max(bsize.x - 1, bsize.y - 1); bsize.y = Math.max(bsize.x - 1, bsize.y - 1); button.setSize(bsize); shell.setSize(bsize); shell.open(); GC gc = new GC(shell); Image image = new Image(control.getDisplay(), bsize.x, bsize.y); gc.copyArea(image, 0, 0); gc.dispose(); shell.close(); ImageData imageData = image.getImageData(); imageData.transparentPixel = imageData .palette.getPixel(greenScreen.getRGB()); return new Image(control.getDisplay(), imageData); }
The result now looks like the picture below.
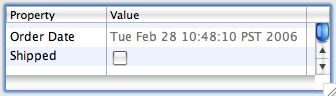
It’s not pixel perfect but closer.
It’s based on Florian Potschka’s version of makeShot as found in the comments to the original post. Replacing your makeShot method with the one above makes the background of the checkbox transparent. It’s not perfect: we use a random near white background color as our ‘green screen’ color in order to get the right antialias color in the edges. But this will also make any pixels with exactly this color inside of the widget shine through. Hopefully there won’t be many. Given enough time somebody will add checkbox support to arbitrary table cells in SWT and this hack will be made obsolete.
Here’s the complete snippet (untested):
package de.fhmracing.glasseye.canexplorer.gui.transmit; import org.eclipse.jface.resource.JFaceResources; import org.eclipse.jface.viewers.ColumnLabelProvider; import org.eclipse.jface.viewers.ColumnViewer; import org.eclipse.swt.SWT; import org.eclipse.swt.graphics.Color; import org.eclipse.swt.graphics.GC; import org.eclipse.swt.graphics.Image; import org.eclipse.swt.graphics.Point; import org.eclipse.swt.widgets.Button; import org.eclipse.swt.widgets.Control; import org.eclipse.swt.widgets.Shell; public abstract class EmulatedNativeCheckBoxLabelProvider extends ColumnLabelProvider { private static final String CHECKED_KEY = "CHECKED"; private static final String UNCHECK_KEY = "UNCHECKED"; public EmulatedNativeCheckBoxLabelProvider(ColumnViewer viewer) { if (JFaceResources.getImageRegistry().getDescriptor(CHECKED_KEY) == null) { JFaceResources.getImageRegistry().put(UNCHECK_KEY, makeShot(viewer.getControl(), false)); JFaceResources.getImageRegistry().put(CHECKED_KEY, makeShot(viewer.getControl(), true)); } } private Image makeShot(Control control, boolean type) { // Hopefully no platform uses exactly this color because we'll make // it transparent in the image. Color greenScreen = new Color(control.getDisplay(), 222, 223, 224); Shell shell = new Shell(control.getShell(), SWT.NO_TRIM); // otherwise we have a default gray color shell.setBackground(greenScreen); Button button = new Button(shell, SWT.CHECK); button.setBackground(greenScreen); button.setSelection(type); // otherwise an image is located in a corner button.setLocation(1, 1); Point bsize = button.computeSize(SWT.DEFAULT, SWT.DEFAULT); // otherwise an image is stretched by width bsize.x = Math.max(bsize.x - 1, bsize.y - 1); bsize.y = Math.max(bsize.x - 1, bsize.y - 1); button.setSize(bsize); shell.setSize(bsize); shell.open(); GC gc = new GC(shell); Image image = new Image(control.getDisplay(), bsize.x, bsize.y); gc.copyArea(image, 0, 0); gc.dispose(); shell.close(); ImageData imageData = image.getImageData(); imageData.transparentPixel = imageData.palette.getPixel(greenScreen .getRGB()); return new Image(control.getDisplay(), imageData); } public Image getImage(Object element) { if (isChecked(element)) { return JFaceResources.getImageRegistry().get(CHECKED_KEY); } else { return JFaceResources.getImageRegistry().get(UNCHECK_KEY); } } protected abstract boolean isChecked(Object element); }
Hope it’ll help somebody.
]]>In our last article, Building an IT infrastructure with a sub-3,000 budget we discussed the possibility to build an extremely cheap, yet modern IT infrastructure. Now a couple of weeks later, I’ve actually deployed a setup based on that article.
The final system I deployed differed slightly from the specs provided in the previous article. For instance, instead of 10 clients as the article stated, my deployment only included 4 clients (at this point). Other than that, the hardware used was very similar to the article. Below is a list of all the components that was purchased and the approximate price in dollars.

Note that I decided to buy three different brands of hard drives to reduce the chances of having two drives collapse at the same time (two drives from the same batch are more likely to collapse around the same time than two random drives).
The company already had a handful of semi-obsolete computers that would work fine as clients in the new environment. Also, as in most organizations there were already other peripherals available that I had to make working in this new infrastructure. Fortunately, this went smoother than what I had anticipated. The peripherals were as follows:

The Server
The server is the heart of this environment (as in most environments), therefore, I’ll start describing the setup of the server first. (I’m not really going to describe what LTSP is, and instead kindly refer you to the previous article for an introduction on the topic).
The initial plan, as I described in the previous article, was to install the 64-bit version of Ubuntu 6.06.1 LTS Server on the server, primarily because of the Long Time Support. Unfortunately it turned out to be a bad choice for two reasons:
1) Ubuntu 6.06.1 has quite limited support for LTSP. Although many of the features work fine, some features such as sound-forwarding to the clients are not implemented. It would quite likely be possible to modify the 6.06.1-setup to support sound as well, but I decided to save some time and just switch over to 7.04 server instead.
2) I was forced to use the 32-bit version instead of the 64-bit version. Although I really tried to avoid this, the software support in the 64-bit version didn’t meet my requirements. For instance, I didn’t manage to print from Wine to Cups in the 64-bit version due to some problem with libcups. Moreover, I discovered that there is no Flash support in the 64-bit distribution. Since many websites today require Flash, I had no choice but to use the 32-bit distribution.
So we decided to use the 32-bit version of Ubuntu 7.04 Server. The next problem I came across was how to partition the hard drives. In contrast to what my previous article stated, it turns out that /opt/ltsp/i386 only includes the boot-environment for LTSP, and not the entire system. Therefore it makes little sense to have an 800GB RAID5 array devoted to it. Once the clients have booted up, they log into the core-server. Because of this, I had to change the partitioning strategy. What I ended up doing was to create two partitions on the RAID5 array: one of 795GB to be used for / and one 5GB to be used for swap. I did discover one problem with this setup though: Grub had problems booting off a software RAID array. After some research, I found that it’s possibly to boot Grub from a software RAID, but it required some hacking. Because of this, I decided to create a small partition on the stock hard drive for a /boot and use the remainder of that drive for backup (mounted as /backup). The problem with this setup is that we have a single point of failure – the stock hard drive. Although nothing important is kept on this drive (unless we need to recover our backups), a failure of the drive would still prevent the system from booting.
The hardware
APC Smart-UPS SC 450VA
The only piece of hardware that requires a bit configuration other than the RAID is the UPS. Fortunately setting up this particular brand of UPS is dead simple. Just install the NUT package and modify your configuration files to match the following:
/etc/nut/ups.conf
[ups]
driver=apcsmart
port=/dev/ttyS0
desc="UPS for BLServer1"
sdtype=0
/etc/nut/upsd.conf
ACL all 0.0.0.0/0
ACL remote 192.168.10.0/24
ACL localhost 127.0.0.1/32
ACCEPT localhost
ACCEPT remote
REJECT all
/etc/nut/upsd.users
[monuser]
password = ups_password
allowfrom = localhost
upsmon master
/etc/nut/upsmon.conf
MONITOR ups@localhost 1 monuser ups_password master
and edit /etc/default/nut to
START_UPSD=yes
START_UPSMON=yes
Brother MFC-8460N
Setting up the network printer was a breeze. Just enter the IP address and you’re set. What surprised me a bit was that even the network scanner worked. After installing the Linux driver from Brother’s homepage and following the instructions, the scanner was up and running in less than 5 minutes.
Brother HL-2040
This printer was locally connected, and once it was added in LTSP (see the next section), the printer worked without any problems.
Dymo Labelwriter 400 Turbo
The printer was connected locally to one of the workstations and added without any problems using the pbm2lwxl-driver (ex. CoStar LabelWriter II). I did not spend much time with this printer, but according to openprinting.org the printer is supposed to work fine in OpenOffice with a specific template matching the paper size in the printer.
Setting up LTSP
As described earlier, the way I described LTSP in the prior article was slightly incorrect. Instead of having the entire environment in /opt/ltsp/arch, the clients actually log into the server as if they were local users. Because of this, the first thing we need to do is to install the desktop environment (since the server-edition comes without this). To do this, simply run:
# sudo apt-get install ubuntu-desktop
Note that this will take quite some time, and I would encourage you to use the installation CD as the source unless you have a very fast internet connection.
Once this is done, it’s time to set up LTSP.
# sudo apt-get install openssh-server
SSH is required to run LTSP, since the traffic from the clients runs through an SSH tunnel
# sudo apt-get install ltsp-server-standalone
Install the LTSP-software
# sudo ltsp-build-clients
Build the client environment. This will take a while.
It’s important that you install the ‘standalone’ edition, else you won’t get the dhcp-server that enables the clients to boot from the actual server. Once you’ve run all the commands above without receiving any errors, you need to make some changes to the dhcp-server. Go ahead and edit /etc/ltsp/dhcpd.conf with your favorite editor to match your network.Then restart the dhcp-server:
# /etc/init.d/dhcp3-server restart
If you changed the IP-address of your server after you ran the installation of ltsp-server-standalone, you need to update the SSH-keys. Do this by running:
# ltsp-update-sshkeys
Setting static IP on clients and allowing local printers
Once you have LTSP configured, you might need to access local devices on the clients. In my case, I had a couple of locally attached printers (both USB and Parallel). To enable the use of these, the first thing you want to do is to set a static IP for the client that holds the printer, based on the MAC address. To do this, we first need to configure the DHCP server to assign a static IP to the client. Edit /etc/ltsp/dhcpd.conf and add:
host ExampleWS1 {
hardware ethernet 00:01:02:03:04:05;
fixed-address 192.168.10.21;
option host-name "ExampleWS1";
}
Now we need to tell LTSP to share the printer assigned to that given workstation. Edit /opt/ltsp/i386/etc/lts.conf and add
[00:01:02:03:04:05] #ExampleWS1
PRINTER_0_DEVICE=/dev/lp0
for sharing a parallel port attached printer, or
[00:01:02:03:04:05] #ExampleWS1
PRINTER_0_DEVICE=/dev/usblp0
for sharing an USB printer.
Once you’ve added this, you need to restart the DHCP server as well as the local client to receive the new IP (or wait for the current IP lease to expire). Now all you need to do is to add the printer using TCP/IP printing with the above IP as the IP address and the appropriate driver for the printer.
That’s it for LTSP. Your server should be ready to have your clients boot off of it now.
Creating a shared space
This part was something that I anticipated to be very simple, but it turned out to be more complex. My plan was to create a folder (/home/shared) and simply just set the owner of that folder to the same group in which I had placed all the desktop users. Although this seemed to work fine at first, a problem appeared when a user created a folder inside of /home/shared. The problem was that all the other users only had read, and not read and write permission to that folder. This means that if User A creates a folder in the shared space, User B cannot rename or delete that folder, which is unlikely to be desirable. After a couple of attempts with chmod, I gave up and started to look for other solutions (correct me if I’m wrong, but it appears as Linux does not inherit folder permission like FreeBSD for instance does). Instead, I found the solution in umask. By editing /etc/profile and changing umask from 022 to 002. What this means is that all files created by the users now have read and write permission by all users in the group. Although this might be considered a security problem, it was the only solution I could find. However, since this is a closed environment, I wouldn’t consider it a very serious problem. Yet, you probably don’t want to have a 002 umask for root and probably want to edit /root/.profile and set umask to 022.
The Clients
Setting up the clients was the easiest part. Just plug in a new Gigabit network adapter and set the BIOS to boot off of it and you’re done. However, I also unplugged the hard drives from the clients to reduce the noise.
The Verdict
Overall the implementation was quite easy. Setting up the LTSP environment was really easy and probably took less than an hour. What I by far spent the most time on was to try to make Wine run the required Windows software (SPCS Administration 2000 Nät). However, after spending about two days hacking configuration files and researching, I threw in the towel – the software just didn’t run well (I primarily blame the software vendor, Visma Spcs, for a very poorly written software with very strange network behavior). Instead, I had to install VMware Server on the Server to run Windows XP (I initially tried Windows 98, since I had a bunch of licenses just laying around, but SPCS Administration 2000 Nät failed to work there too). This was of course undesirable, but with the time constraints I had this turned out to be the only realistic solution. The setup was quite straight forward (using this guide). In order to connect to Windows from the LTSP environment, I simply enabled RDP in Windows and used rdesktop to connect.
The d’oh and ahh’s
* /opt/ltsp/arch only holds the boot environment, not the entire LTSP desktop environment. Once the clients have booted up, they log into the core-server.
* The Windows software that I was supposed to run under Wine didn’t play nice. The only way I got this working was through a Windows XP session running under VMWare Server. Unfortunately this requires a Windows license. However, it’s likely that the company will switch to a web-based program instead, eliminating the requirement.
* I had problems using certain characters when connecting to Windows from the LTSP environment using TightVNC and RealVNC. I solved this problem by switching to Windows’ own RDP-protocol.





“No way! That’s impossible.” Well, actually it’s not. Using Open Source technology, it’s actually possible to create a competitive IT infrastructure at very low costs. Not only does Open Source software enable you to create more customized solutions to better fit your needs, but it also means that you can spend your budget on hardware – not software.
Last month I was asked by a company to figure out how to ‘modernize‘ their IT infrastructure with a minimal (almost non-existing) budget. After plenty of thinking and research, I came to realize that the only way to do this was to use some kind of thin-client solution. The solution that I found to fit my needs the best was Linux Terminal Server Project (LTSP). LTSP utilizes network boot (we will use PXE) to boot the clients directly from the server. Therefore, we can use obsolete clients without hard drives (to reduce the noise) as thin clients. The only thing we need on all the clients is a fast network adapter with PXE-support.
Some of the widest adoption of LTSP has been within K12 the education field. Since many educational institutions are working with very tight budgets, LTSP has a strong advantage. It is a way to save costs without having to compromise too much on usability. Edubuntu is a Linux distribution that targets educational institution. What makes Edubuntu very interesting is that it comes out-of-box with LTSP support, which enables system administrators with limited knowledge of Linux to get a thin-client setup running with little effort. Since Edubuntu is closely related to the regular Ubuntu, it’s not very hard to get Ubuntu up and running as an LTSP server.
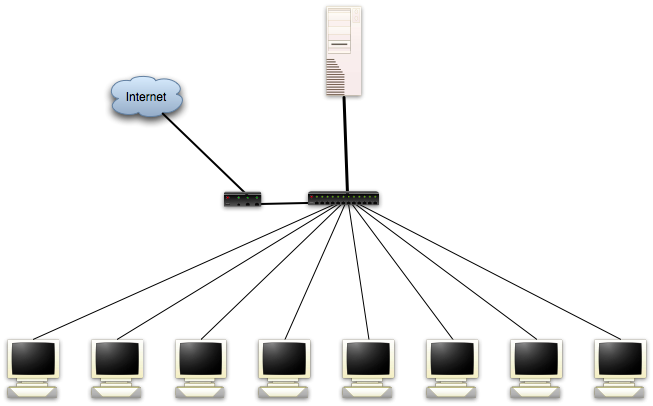
The Hardware
With a very limited budget, I realized that a thin-client solution would be the most realistic approach. As the name implies, the clients are thin and most of the load will be on the server. Therefore we will spend most of the money on a solid server. After a good amount of research to find a cheap, yet powerful and expandable server, I found the HP ProLiant ML115. The server comes with a 64 bit 2.2GHz Dual Core AMD Opteron CPU, which will serve our needs well. However, it only comes with 512Mb of RAM, which is insufficient for the number of users we intend to have. Therefore we’ll need to purchase some additional RAM. The RAM consumption estimates varies across different LTSP projects, ranging from 256Mb + 32Mb per client to 1024Mb + 64Mb per client. However, since I’d rather be on the safe side, I’d recommend that you purchase another 2Gb of RAM (total 2.5Gb) and put in the server (1024Mb + 150Mb per client).
The next thing we need to add is a Gigabit switch to reduce the possibility of having the network as a possible bottleneck (note that I’m not sure if a 10/100 Mbit network would actually create a bottleneck in this setup, but I rather be safe than sorry). Since Gigabit is cheap today, going Gigabit all the way seems like a reasonable move. Therefore, I’ve budgeted for 10 Gigabit network adapters (with PXE support) and a 16 ports Gigabit switch (the HP server comes with Gigabit network adapter).
Now we need somewhere to store the users’ data with high security and performance. Since we’re on a limited budget, we will use a software RAID solution rather than a high-end hardware RAID solution. A RAID-5 setup on three SATA disks using Linux’s software RAID is probably the cheapest and most reliable for the price. This will allow us to increase performance while we also gain protection against loss of any one drive without loss of any data. Moreover, we also use a separate OS disk to reduce the I/O load.
Because everything is both stored and running on the server, it’s crucial that we protect the equipment from power failures and spikes (the server by itself is a single point of failure). Therefore I’ve added an UPS to the budget (1100 VA) that will not only protect our hardware but also reduce server downtime.
The last thing we need to add is the clients. It’s quite likely that you have a many retired PCs (preferably P2>). If not, you’re likely to find a many of these computers for sale (or for free) in your local classified adds section. If Craigslist is available where you live, this is a great source to find this kind of hardware. Even though many of you will get these computers for free, I’ve budgeted $50 per client.
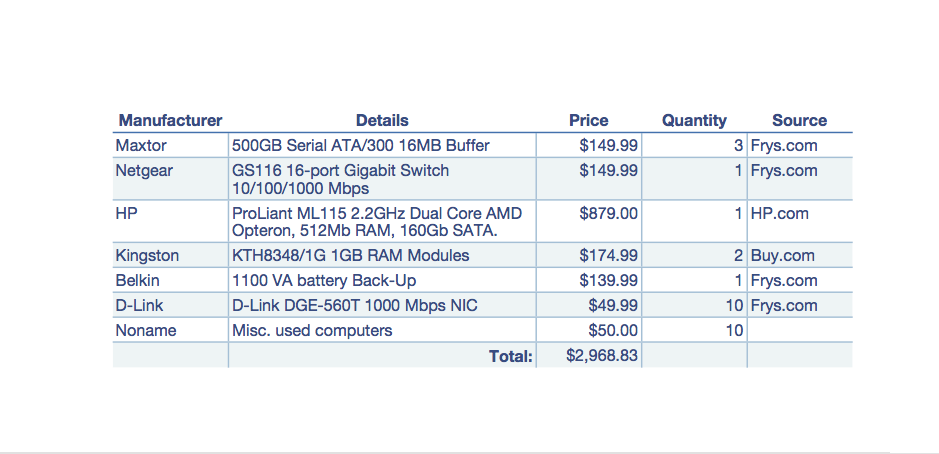
The Software
I’ve divided this section into two parts: Server and Desktop. Although all software will be running on the server, the users will only see the software on the Desktop side, which is why I have separated them.
Server
As already touched upon, the server will be running Linux. To be more precise, I’ve decided to use Ubuntu Server 6.06.1 LTS Server (64-bit). The reason why I didn’t chose to use the most recent version (7.04) is to minimize the administrative effort. Since 6.06 is the Long Time Support (LTS) version, the Ubuntu team will supply this version with security patches and updates for a longer period than the 7.04 release (6.06 LTS Server will be supported until 2011).
Installing Ubuntu is very straight forward. The only thing to consider in this setup is to make sure we install the system on the hard drive that came with the server and not the RAID-5 array.
Configuring the RAID 5 can be done though a couple of different ways. You can either do this during the installation (with Ubuntu’s graphical utility), or wait and set it up afterward in the console (see the Software RAID HOWTO for details). After setting up the RAID, go ahead and mount it to /raid or something similar.
Now it’s time to set up LTSP, which is the foundation of our cost-saving solution. There are a couple of different ways to do this, but the one I found to be most useful was to follow a guide from Novell (strangely enough) available here. You might also want to take a look at Ubunut’s Thin-client documentation.
Before you start the installation, go ahead and symlink /opt, which is where LTSP will be installed, to within you RAID array (ln -s /opt /raid/opt). This will install all the packages on the RAID array instead of the system disk. Finally, what you will want to do is to add a test-user (or a real user – it’s your call). This is done by simply using the user-management tool in the Ubuntu. Note that you probably want to have the home-dir of the users on the RAID array. To achieve this, you can either symlink the entire /home to /raid/home or just set the home-dir to /raid/home/user in the user-creation process.
Desktop
The LTSP setup comes with the most common software used in a corporate environment. This includes:
* FireFox – A great web browser
* Open Office – A Microsoft Office replacement
* Evolution – A Microsoft Exchange replacement
* The Gimp – An Adobe Photoshop replacement (arguably less powerful)
Plus a long line of other applications such as PDF-viewer etc.
You might also want to install is Wine. Wine is a Windows emulator which will run (legally) without any Windows license. Although it does not run all Windows software, many applications work very well.
If you have needs outside of the applications listed above, there’s more available. Any software that runs in a Linux environment (pretty much) will run on these thin clients. Although I haven’t tested it, you should be able to run a fully emulated Windows environment using a virtualization software such as VMWare Workstation or CPU/RAM intense softwares such as MatLab or CAD software.

The Clients
The last part is to get the clients to actually boot over the network. If you decide to use a different network card than the one specified in the budget above, make sure it supports PXE booting. Many budget NICs don’t support this feature. There are also other ways to boot but I’m not going to cover that in this article (such as floppy, CD etc.).
The Pros and The Cons
Although this approach is a very good way to create an updated desktop environment while at the same time minimizing the administrator’s job, it does come with some drawbacks. Unfortunately many companies today are stuck with custom software that only runs on Windows. Although Wine offers a great emulation software, you might be forced to purchase a license of VMWare Workstation (and Windows) to run some specialized applications. If you’re lucky, your custom software was written in Java, and it will actually run on Linux as well.
Another thing to consider is the transition from the old environment (quite likely from Windows) to this new environment. Although the transition is likely to be smooth for a crew of young people, members of the older generation (40+) are likely to require some training before being able to use the system fully. Both Open Office and Firefox work very similar to their Windows-counterparts, but Evolution is slightly different.
Another pro is the lack of viruses on Linux. Since we’ve left Windows behind, the likeliness of being infected by a virus is almost zero.
In summary, utilizing a solution such as this might or might not suite your needs. If you do have the flexibility to use Open Source software in your organization and are able to run your customized software either emulated or use a web-based interface, this is a great way to reduce costs from the IT budget and spend them in a way that benefits the company better.
Update: I’ve now actually deployed this solution at a company. For information about how it went, go ahead and read “Deploying the sub-$3,000 IT-infrastructure.”

Whenever virtualization comes up, the idea of grid computing isn’t far away as enterprises wish to maximize server utilization by turning their data centers into grids that each deliver the ‘services’ of CPU, memory, ports and so on. But in this brave new world of virtual machines and grid processing there is an element missing. If you’re moving your computing over to a grid computing model, why is there no corresponding grid storage model?
The commercial open source startup Cleversafe has that corresponding model. By employing a mathematical algorithm known as an Information Dispersal Algorithm, found in the cryptographic field of research, Cleversafe separates data into slices that can be distributed to different servers, even across the world. But it’s much more than just slicing and dicing: the algorithm adds redundancy and security as it goes about its task. When the algorithm is done, each individual slice is useless in isolation, and yet not all slices are needed to reconstruct the original data. In other words, your data is safer both in terms of security and in terms of reliability.
Cleversafe is not the first entity to come up with such a scheme. The idea of an Information Dispersal Algorithm is known from Adi Shamir’s paper ‘How to Share a Secret’ and other publications. When we met up with Cleversafe’s Chairman and CTO Chris Gladwin at LinuxWorld, he mentioned that the Information Dispersal Algorithm had been used in many applications before – even to store launch codes for nuclear weapons securely.
The scheme is different from a simple parity scheme in that you can configure how many redundant pieces you want. With parity as found in common RAID setups, you can lose any one storage unit in the set. With an Information Dispersal Algorithm, you can make your system resistant to failure or corruption of any one, two or indeed any number of units in the set. If there’s a strike in your data center in Texas, and your German data center is on fire, your data will still be fully accessible through the remaining servers provided you began with a sufficient number of servers. And as opposed to the brute force solution of multiple mirrors of the data, the dispersal algorithm has a much smaller overhead.
Google is a well known proponent of the brute force solution: the Google File System implementation suggests that the best method to keep your data continuously available is to keep three copies of it at all times. Cleversafe is a smarter system. If you have 16 slice servers (known as pillars in Cleversafe terminology) with a redundancy of 4 slices (known as the threshold) you can lose up to four servers simultaneously and still retain your data. At the same time the total overhead in storage space is only 4/12 – 33% of the space. The advantage as compared to Google’s three copies method is clear: with three copies you only protect yourself against the failure of any two servers and yet you pay a much greater price with a total of 200% storage and bandwidth overhead. And that’s not all. While you’re storing two additional copies of your data, you have effectively tripled the risk of that data being stolen. When a careless system administrator forgets the backup tapes in his car over night and the car gets stolen, all those credit card numbers or what have you will be out in the wild, even that only one out of three locations was compromised. In our Cleversafe example, 12 separate servers would have to simultaneously be compromised – quite unlikely by comparison.
Cleversafe is not alone and there are other actors on the software market such as the PASIS system. PASIS’ home page describes functionality very similar to Cleversafe’s: “PASIS is a survivable storage system. Survivable storage systems can guarantee the confidentiality, integrity, and availability of stored data even when some storage nodes fail or are compromised by an intruder.” None the less, Cleversafe appears to be a step ahead of its competitors at this time and is poised to be the first to deliver grid storage to a wider market.
While the Cleversafe software is developed as open source through the Cleversafe Open Source Community at cleversafe.org, there is a commercial company behind Cleversafe: Cleversafe, Inc. Cleversafe, Inc. plans to generate revenue by offering a storage grid for rent based on the Cleversafe technology. “The market for a more secure, more cost effective storage solution is enormous,” says Jon Zakin, CEO of Cleversafe in a press release issued in May.
The Cleversafe project is available as Open Source under the GPL 2.0 License. The version online is apparently an early alpha version and is not ready for production use. According to Mr. Gladwin, there will most likely be a new version within a month, and sometime in the beginning of the next year Cleversafe may be ready for production use. In the meantime, you can download the current alpha version of the software at the Cleversafe Open Source Website. You can read more about the algorithm at Cleversafe.org’s wiki, and there’s also a flash video describing the idea available.
As I have done before, I will attempt to make a terse summary. I assume you have or confidently can acquire knowledge of PHP and C. I’m a big fan of simple cookbook ‘recipe’ like guides, so here we go. Hold on to your hat.
Step 1: Compile PHP With Debugging Enabled
When developing your own module, you’ll want to enable debugging in PHP. This will generate error messages which may contain additional information beyond an unhelpful ‘segmentation fault’ when your module crashes.
In FreeBSD, just go into your ports, and do make config. Turn on the ‘debugging’ option and recompile PHP and its modules. Other platforms are similar; if you’re compiling from source by hand, take a look at the output of ./configure --help and you’ll find the right option for your version.
Before you start working on your module, make sure everything is in order with your server and that your extensions.ini file looks good. In my experience, rebuilding PHP under FreeBSD sometimes causes modules to appear twice in the extensions.ini file, and you may wish to be wary of this.
Step 2: Set up a project skeleton
PHP comes with great support for developing your module. There are a couple of scripts and configure related tools that automate almost all the work for you.
First, create a config.m4 file in your new project. (There’s even a tool that does this for you – ext_skel – but we’ll do it by hand for the purposes of this guide.) Here’s a bare bones config.m4 file for an extension named “pwwext”:
dnl config.m4 for extension pww PHP_ARG_ENABLE(pwwext, whether to enable pww support, [ --enable-pwwext Enable pww support]) if test "$PHP_PWWEXT" != "no"; then PHP_NEW_EXTENSION(pwwext, pwwext.c, $ext_shared) fi
You’ll also need some source code. Lets begin with the header file, which we’ll call pwwext.h. Lets write a minimal header:
#ifndef PHP_PWWEXT_H #define PHP_PWWEXT_H #define PHP_PWWEXT_EXTNAME "pwwext" #define PHP_PWWEXT_EXTVER "0.1" #ifdef HAVE_CONFIG_H #include "config.h" #endif #include "php.h" extern zend_module_entry pwwext_module_entry; #define phpext_pwwext_ptr &pwwext_module_entry #endif /* PHP_PWWEXT_H */
In my experience, it’s often a waste of time to learn things before you need them. This is a good example of that: the header code does pretty much what it appears to do, and more in depth knowledge is not strictly needed. In short it exposes the entry point of the module and brings in the most important header files.
Step 3: The Actual Source
Finally, we’ll need the file we referred to in config.m4 previously. It’s the main source file, pwwext.c:
/* * This extension enables cool pww functionality. */ #include "pwwext.h" PHP_FUNCTION(pwwext_calculate) { long a, b; /* Get some params. */ if (zend_parse_parameters(ZEND_NUM_ARGS() TSRMLS_CC, "ll", &a, &b) == FAILURE) { RETURN_NULL(); } if (a < = 0) { zend_throw_exception(zend_exception_get_default(), "First argument can't be negative nor zero.", 0 TSRMLS_CC); RETURN_NULL(); } /* PHP preallocates space for return values, so its important to use these return macros. */ RETVAL_LONG(a+b); return; } static function_entry php_pwwext_functions[] = { PHP_FE(pwwext_calculate, NULL) { NULL, NULL, NULL } }; zend_module_entry pwwext_module_entry = { #if ZEND_MODULE_API_NO >= 20010901 STANDARD_MODULE_HEADER, #endif PHP_PWWEXT_EXTNAME, php_pwwext_functions, /* Functions */ NULL, /* MINIT */ NULL, /* MSHUTDOWN */ NULL, /* RINIT */ NULL, /* RSHUTDOWN */ NULL, /* MINFO */ #if ZEND_MODULE_API_NO >= 20010901 PHP_PWWEXT_EXTVER, #endif STANDARD_MODULE_PROPERTIES }; #ifdef COMPILE_DL_PWWEXT ZEND_GET_MODULE(pwwext) #endif
There are a couple of important structures here. The variable php_pwwext_functions lists all the functions we wish to expose from the module. In our example, we’re only exporting a single function.
Then we have the pwwext_module_entry structure which truly is the entry point into your module. If you would look near the sixth line in the structure you’d see a pointer to our list of functions, for instance.
Step 4: Compiling and Running
Finally, we’ll want to build the actual module. The command phpize will get everything in order for a compilation based on your configuration. After phpize is done, the normal configure make dance is all we need. Make note of the ‘--enable-pwwext‘ argument to configure.
[~/pwwext]$ phpize./configure --enable-pwwextmake
That’s all there is to it. Your module should now be built and almost ready to go. To wrap up, you’ll need to install the module in your PHP extensions folder. If you don’t know it already, run php -i to find the right folder. For me, the result is,
$ php -i|grep extension_dir extension_dir => /usr/local/lib/php/20060613-debug => /usr/local/lib/php/20060613-debug
so I’ll go ahead and copy the module into /usr/local/lib/php/20060613-debug:
# cp modules/pwwext.so /usr/local/lib/php/20060613-debug/
There’s one last step we’ll have to do. We need to add the module to the list of extensions in your php.ini or extensions.ini file. Locate the section with multiple lines beginning with extension=... and add your own line. For me, this line would do it:
extension=pwwext.so
Step 5: Does it work?
Finally, we can test our new module. Run,
$ php -m
and make sure your new module is in the list.
If all is well you should be able to use your new function from any PHP script. For me, this was the final result:
$php -r'echo pwwext_calculate(1, 2);' 3 $ php -r'echo pwwext_calculate(-1, 2);' Fatal error: Uncaught exception 'Exception' with message 'First argument can't be negative.' in Command line code:1 Stack trace: #0 Command line code(1): pwwext_calculate(-1, 2) #1 {main} thrown in Command line code on line 1
Now you have a bare bones module that does something. All that remains now is to change that one function to do something useful and you’re well on your way.
You’ll undoubtedly need more reference material going forward. Php.net is the logical starting point: The Zend API. If that’s not enough, Sara Golemon wrote a whole book about the subject: ‘Extending and Embedding PHP’.
Good luck, and don’t forget to turn off PHP debugging when you’re done.