If you’ve followed us for a while, you might remember our article ‘Selecting an Accounting System’. Not too many things have changed since then. The developers over at Quickbooks are still not competent enough to write an OS independent web-app, and no other major events have occurred. The most interesting thing that have happened since we wrote the article was that SQL-Ledger silently changed license from GPLv2 to SQL-Ledger Open Source License. Although we would rather have seen SQL-Ledger staying GPLv2, we don’t really blame them. The company needs to make some money in order to survive. So, despite the change of license, we still decided to use SQL-Ledger as our accounting system. At least for now.
Enough about that, let’s get started. First time I installed SQL-Ledger I ran into a couple of problems. Even though I spent a fair amount of time doing research on how to set everything up, I still hit a couple of speed bumps. Since I’m quite new to PostgreSQL, some of my problems were related to this. Some other problems were related to the fact that the manuals did not really match what I saw on the screen.
Now, let’s get started. First we start with updating the ports to make sure we’re getting the latest version.
# portsnap fetch; portsnap update
After updating our ports-tree, we need to install PostgrsSQL. When writing this post, the 8.2-series is the latest stable series.
# cd /usr/ports/database/postgres82-server/
# make config
Select the flags you prefer. The only flag I changed from the default was the optimization flag. Not that I know if it makes much of a different, but if you’re compiling it you might as well try to build more optimized binaries.
# make install
Now Postgres is installed. However, in the normal FreeBSDish manner, we need to enable it in rc.conf before we can fire it up.
Edit /etc/rc.conf and add postgresql_enable=”YES”
When you’ve activated Postgres, we first need to initiate the database, and then start the service.
# /usr/local/etc/rc.d/postgresql.sh initdb
# /usr/local/etc/rc.d/postgresql.sh start
Voila, now we have Postgres initiated and up running.
Let’s take a look at the package we’re actually interested in installing: SQL-Ledger.
We’re just going to use a simple ports-installation of SQL-Ledger.
# cd /usr/ports/finance/sql-ledger
# make install
After installing the package, we need to make changes to Apache in order to enable SQL-Ledger. Simply add the following line at the appropriate location in your httpd.conf or ssl.conf:
Include /usr/local/etc/sql-ledger-httpd.conf
To make sure our Apache-file is intact, we run:
# apachectl -t
And if that went well, we run:
# apachectl restart
The only step remaining now is some database-related stuff.
Since I’m not an expert at Postgres, I might not be explaining this in the best way. Anyways, I’m just trying to share my experience, since this was the step where I ran into some speed bumps when first setting up SQL-Ledger. The problems I was facing was that the prompts I received differed quite a bit from the ones found in the various manuals I read before installing.
First, log into the Postgres user
# su - pgsql
When you’re logged in, we need to create a user for SQL-Ledger:
# createuser -d -P sql-ledger
Enter password for new role:
Enter it again:
Shall the new role be a superuser? (y/n) n
Shall the new role be allowed to create more new roles? (y/n) y
Note that if you remove the -P, you won’t be prompted for password. However, I personally prefer setting a password here.
Lastly, we need to copy the template.
#createlang plpgsql template1
Hopefully that went without any problems. Now it’s time to surf into SQL-Ledger to make the final configurations. Open your browser and surf into http://

Select the “Database Administration” link.
Use the user ‘sql-ledger’ and the password you assigned when creating it. For ‘connect to,’ use ‘template1.’ When you’re done filling that out, hit ‘create dataset.’
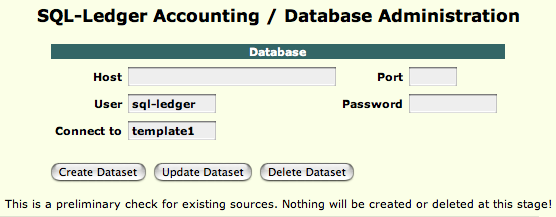
The next screen that will pop up is the Create Dataset-screen. Here you need to set the name of your dataset. Use only lower-case letters. I’d suggest the name ‘sql-ledger’ to keep things from being complicated later on. For ‘encoding,’ select UTF8. As for the ‘chart of accounts,’ it really depends on what business you’re setting up SQL-Ledger for.
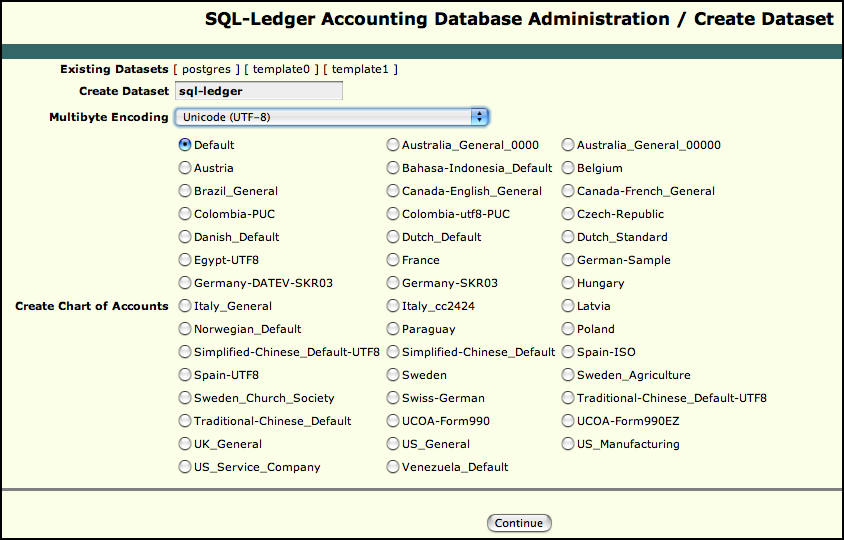
You’re done! All you need to do now is to set up the users. Since this is quite straight forward, I’m not going to cover that.
For more information, please visit sql-ledger.org. You might also want to take a look at this ‘unofficial’ manual (the official one costs $190).
Edit 1: Dieter Simader, the founder of SQL-Ledger, e-mailed me to point out that the only non-GPL’d version of SQL-Ledger is the 2.8-series. The 2.6-series used by FreeBSD ports is still under GPL.