Until a couple of days ago, my bookshelf was filled with binders with old lecture notes from school. The truth is that I don’t think I ever opened one of these binders after I finished the final for the class. Yet, I didn’t want to throw it all away, since it might come handy some day when I want to refresh my memory.
On the other hand these binders really bothered me. They took up space in the bookshelf that I could use for something more useful. So I thought, why don’t I digitalize these papers?
This solution includes:
- A scanner (preferably with ADF)
- A software called PDFLab
- A staple remover
- Quite a bit of time
You may want to use this guide for the archiving of old:
- Bills
- Financial documents
- Lecture notes
- Receipts
1. Preparing your documents
Prepare the documents you want to scan. That means figuring out how you want to group your documents and removing the staples. Since I was scanning lecture notes, the grouping was quite simple. Removing the staples is a boring job, but it needs to be done.

In the process of scanning…
2. Scanning your documents
 This is the time consuming part. Depending on your hardware, the time the scanning takes varies a lot. With the scanner I was using (HP Scanjet 5590), one paper (front and back) probably took about 35 seconds in 150 DPI. If you have a scanner with ADF, it doesn’t really matter that much if it takes 10 or 40 minutes to scan a pile of papers, since you can go and do something else in the meantime.
This is the time consuming part. Depending on your hardware, the time the scanning takes varies a lot. With the scanner I was using (HP Scanjet 5590), one paper (front and back) probably took about 35 seconds in 150 DPI. If you have a scanner with ADF, it doesn’t really matter that much if it takes 10 or 40 minutes to scan a pile of papers, since you can go and do something else in the meantime.
Depending on the software you’re using, the file-output might differ. In the software I was using, the name ‘bus-law_0_0.jpg’ turned out to be working quite well. The first ‘0’ is for the sequence. If for some reason the scanning aborts, you can just continue with ‘bus-law_1_0.jpg’, and the files will still sort in order.
3. Preview and delete blanks
When you’ve scanned in one entire group of documents, select them all and drag them to Preview. Use the arrow-keys to browse through all the documents to make sure they look good. You might want to rotate some documents, or delete some blank pages. I found the shortcut ‘Apple + Delete’ very handy in Preview, since then I can delete the file from Preview, without having to go out in Finder.
4. Convert your documents to a PDF
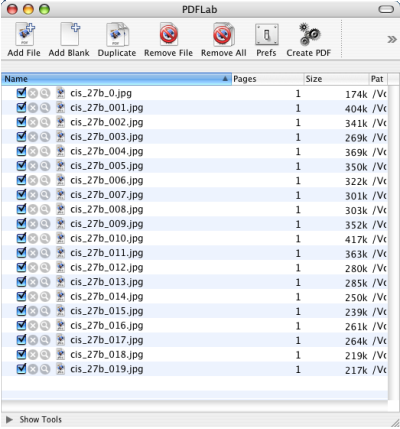
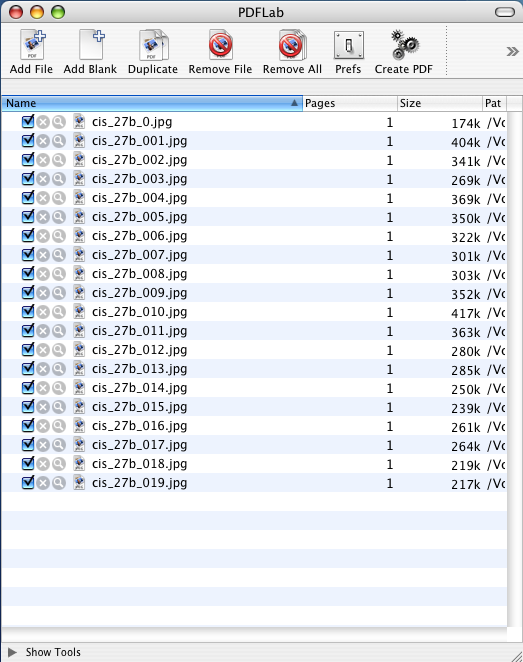
Screenshot of PDFLab
Up to this point you just have a bunch of jpeg files in a folder somewhere. Since this is not very convenient when you browse notes, I wanted to convert every group to a single PDF-file. When doing my research I found a very handy software called PDFLab. The software is a freeware and works really well.
Download PDFLab and fire it up. Now go to the folder where you saved all those jpeg files. Select them all, and drag them to PDFLab. This might take a couple of minutes, depending on your hardware.
When the files are imported into PDFLab, sort them by name by clicking ‘Name’. Now look through the list. If you have file names that go above 100 (‘bus-law_0_0100.jpg’), the sorting might not be done properly, since the file ‘bus-law_0_0103,jpg’ is sorted before ‘bus-law_0_013.jpg’. If you experience this, you need to move around the files manually until they are in the proper sequence.
When you’re happy with the sorting, hit ‘Create PDF,’ and enter an output file-name in the dialog which appears. If the PDF was generated without any errors, you’re all set.
 If you get an error message when generating the PDF, just hit OK, and try to create it again. If this doesn’t work, try to restart the software.
If you get an error message when generating the PDF, just hit OK, and try to create it again. If this doesn’t work, try to restart the software.
5. Delete/Backup the image-files
When you’ve made sure that your PDF is working fine, you can either delete you jpeg files or burn them to a CD just to be safe.
That’s it. You can now throw away all those papers into the recycle bin. The best thing is that you’re never more than a couple of clicks away from your documents.

Empty binders
6. Drawbacks
This solution is not perfect, but it’s sure better than having all those binders in the bookshelf or in a box somewhere. The main drawback of this is that the documents are not searchable. This could possibly be solved with OCR, but according to my experience, OCR is still not powerful enough to recognize all handwriting. OCR also tend to mess up documents which mix text and images. However, if I was able to scan these documents into a PDF with OCR recognition, this would be the optimal solution, since it would both be searchable and consume less space.
Author: Viktor Petersson Tags: guide