Over the last few days, iPhone unlocking has seen a couple of sharp turns. First iPhoneSimFree promised to deliver a commercial solution to unlock your iPhone. Then they hesitated and decided to become a wholesale only company, further delaying their release. Ultimately, they missed the train and the hacking community stepped in (Free iPhone unlock supposedly pending (Updated x2)), and released a free hack: iUnlock by the iPhone Dev Team (no association with Apple).
 Since vendor lock-in is never a good thing for the customer, the release of this software is great news. And as fans of the free market may be aware, cell phone unlocking is legal. But does it work? Playing With Wire decided to find out. We picked up a 4GB Apple iPhone, headed out on the internet and soon found a great unlocking tutorial at modmyiPhone. The guide is Mac specific, but we also stumbled across unlock.no which appears to offer a guide for Windows users – we didn’t try it though.
Since vendor lock-in is never a good thing for the customer, the release of this software is great news. And as fans of the free market may be aware, cell phone unlocking is legal. But does it work? Playing With Wire decided to find out. We picked up a 4GB Apple iPhone, headed out on the internet and soon found a great unlocking tutorial at modmyiPhone. The guide is Mac specific, but we also stumbled across unlock.no which appears to offer a guide for Windows users – we didn’t try it though.
The Unlock Process
The process is a little bit lengthy but everything is done using simple graphical tools. For starters, you need to make sure your iPhone is entirely up to date. iTunes does this for you after you trigger the ‘recovery mode’ of your iPhone, by pressing Sleep and Home for 25 seconds.
The iPhone in recovery mode.
Once you’re in recovery mode you can just connect the iPhone to your computer and iTunes will offer you the option of restoring the phone. Prepare yourself for the first of a couple of lengthy downloads – for us iTunes downloaded 96 MB of software updates (we used iTunes 7.4.0 and iPhone Firmware 1.0.2 for this article). When it’s all done, iTunes will tell you so and you can close down the application.
So now we had an updated but not yet activated iPhone. The Mac application “iNdependence” makes activation a breeze, but this is where the second lengthy download comes into the picture as you have to download the firmware a second time. We did run into a minor snag: when we followed the instructions on the page we couldn’t get the activation to work on our first attempt. Disconnecting the phone, restarting iNdependence and then reconnecting the phone took care of it though – iNdependence unlocked the phone without complaint. Voila, now we had an iPhone that was basically like Apple’s latest iPod, the iTouch: it could play music and video, but it couldn’t make phone calls.
 This is where the Unlock application comes into play. To actually get it onto the phone, you need SSH installed though. Just like the guide says, the AppTapp application allows you to install third party software on your iPhone. We ran into trouble here though: when we ran AppTapp we got an indefinite progress bar. We waited a good 15 minutes for the application to finish, but it never did. What’s worse, our iPhone locked up in ‘recovery mode’ and could no longer be started. We realized that we had left iNdependence running from the previous step, and perhaps this application conflicted with the AppTapp installer. Regardless of the reason, the iPhone was dead at this point.
This is where the Unlock application comes into play. To actually get it onto the phone, you need SSH installed though. Just like the guide says, the AppTapp application allows you to install third party software on your iPhone. We ran into trouble here though: when we ran AppTapp we got an indefinite progress bar. We waited a good 15 minutes for the application to finish, but it never did. What’s worse, our iPhone locked up in ‘recovery mode’ and could no longer be started. We realized that we had left iNdependence running from the previous step, and perhaps this application conflicted with the AppTapp installer. Regardless of the reason, the iPhone was dead at this point.
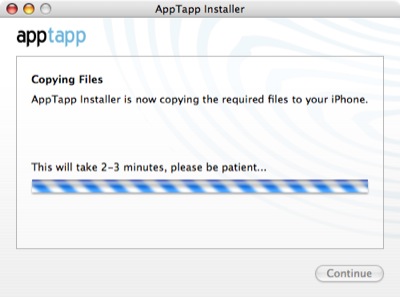
AppTapp never got any further than this for us.
We restarted the iPhone and connected it to iTunes to restore it to factory settings. We were horrified as iTunes crashed very early on in the process. We mentally readied ourselves for creating our own Will It Blend episode, thinking the phone was a goner. Luckily after a full reboot of both the computer and the phone, the software reset went through.
We were back to square one, and had to go ahead and again activate the phone with iNdependence and then go for a second attempt at installing AppTapp. To be on the safe side, we downloaded the most recent version of AppTapp from its homepage. We made sure iNdependence was turned off.
This time we got an error message instead – something about a boot strapping process failing and a reference to the console. So we pulled up Console.app (/Applications/Utilites/Console) and took a look. To our surprise, the iPhone installer software was still working despite the error message.
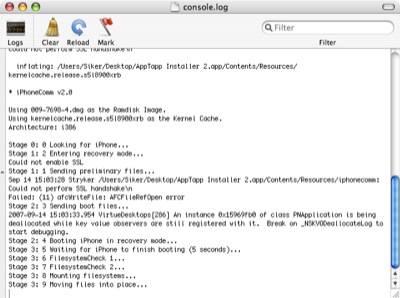
Look! Something is still installing.
A couple of minutes later the phone restarted and all was well. The Installer icon appeared on the iPhone desktop and we could install the required software as described in the guide.
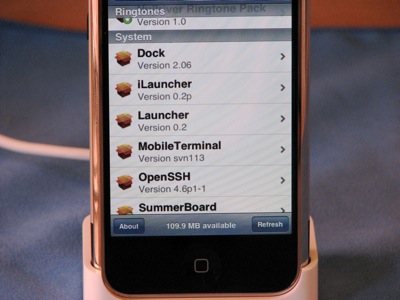
Some of the applications the AppTapp Installer can install.
 In the final part of the guide, the actual Unlock software is installed using SFTP. The guide recommends transferring the application bundle using Cyberduck, but we figured any SFTP client would do it. We had Panic’s Transmit installed, which worked just fine. After copying the files as instructed, and restarting the phone one more time, we finally had the Unlock icon on the iPhone desktop. It was time to install our T-Mobile SIM card and hope for the best.
In the final part of the guide, the actual Unlock software is installed using SFTP. The guide recommends transferring the application bundle using Cyberduck, but we figured any SFTP client would do it. We had Panic’s Transmit installed, which worked just fine. After copying the files as instructed, and restarting the phone one more time, we finally had the Unlock icon on the iPhone desktop. It was time to install our T-Mobile SIM card and hope for the best.
25 minutes later we were making T-Mobile phone calls.
Notes and Observations
During the above process SSH was installed on the iPhone. This allows anyone who knows the default root password to log into your iPhone and do anything they want, as long as the phone is on a wireless network. We strongly recommend that you change your password as soon as possible using the ‘passwd’ from an SSH session.
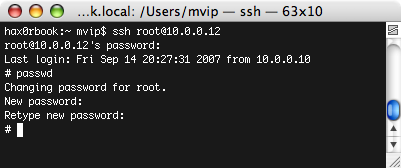
Using SSH to change the default password (dottie).
So far, our iPhone has worked very well with T-Mobile. Initially there was an artifact ‘missed call’ icon hanging around over the Phone icon – a red circle in the upper right corner of the phone. Obviously, visual voice mail isn’t enabled as that’s an Apple and AT&T special feature, but the voice mail indicator works. When you press the icon, the phone calls your voice mail like a regular cell phone would.
Verdict
The Unlock application works just as advertised. Including the time it took us to take photographs and the time we spent resolving our few problems, the whole unlocking process took no longer than 2 hours. At no point was a non graphical tool needed, which surely will come as a relief to some users.
Unfortunately, the process is not entirely simple even with the graphical tools, since there are several opportunities to brick the phone or otherwise get tripped up. Still, if you feel confident with your technical abilities, and you don’t feel confident in AT&T’s cell phone abilities, this is the tool you’ve been waiting for. The iPhone is free.