

Until a couple of days ago, my bookshelf was filled with binders with old lecture notes from school. The truth is that I don’t think I ever opened one of these binders after I finished the final for the class. Yet, I didn’t want to throw it all away, since it might come handy some day when I want to refresh my memory.
On the other hand these binders really bothered me. They took up space in the bookshelf that I could use for something more useful. So I thought, why don’t I digitalize these papers?
This solution includes:
You may want to use this guide for the archiving of old:
- Bills
- Financial documents
- Lecture notes
- Receipts
1. Preparing your documents
Prepare the documents you want to scan. That means figuring out how you want to group your documents and removing the staples. Since I was scanning lecture notes, the grouping was quite simple. Removing the staples is a boring job, but it needs to be done.

In the process of scanning…
2. Scanning your documents
 This is the time consuming part. Depending on your hardware, the time the scanning takes varies a lot. With the scanner I was using (HP Scanjet 5590), one paper (front and back) probably took about 35 seconds in 150 DPI. If you have a scanner with ADF, it doesn’t really matter that much if it takes 10 or 40 minutes to scan a pile of papers, since you can go and do something else in the meantime.
This is the time consuming part. Depending on your hardware, the time the scanning takes varies a lot. With the scanner I was using (HP Scanjet 5590), one paper (front and back) probably took about 35 seconds in 150 DPI. If you have a scanner with ADF, it doesn’t really matter that much if it takes 10 or 40 minutes to scan a pile of papers, since you can go and do something else in the meantime.
Depending on the software you’re using, the file-output might differ. In the software I was using, the name ‘bus-law_0_0.jpg’ turned out to be working quite well. The first ‘0’ is for the sequence. If for some reason the scanning aborts, you can just continue with ‘bus-law_1_0.jpg’, and the files will still sort in order.
3. Preview and delete blanks
When you’ve scanned in one entire group of documents, select them all and drag them to Preview. Use the arrow-keys to browse through all the documents to make sure they look good. You might want to rotate some documents, or delete some blank pages. I found the shortcut ‘Apple + Delete’ very handy in Preview, since then I can delete the file from Preview, without having to go out in Finder.
4. Convert your documents to a PDF
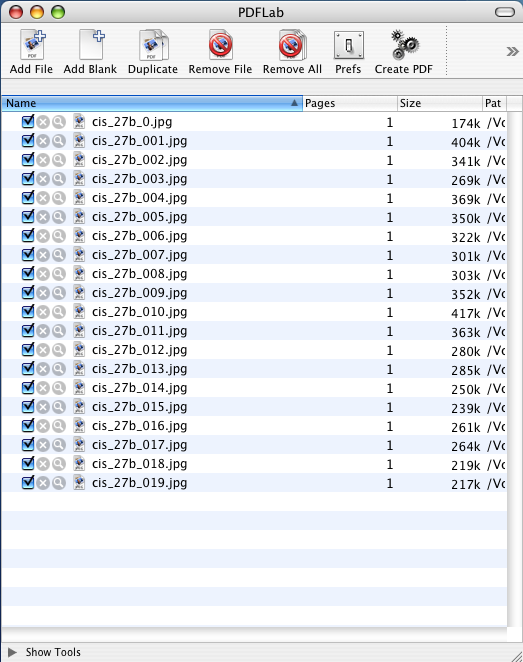
Screenshot of PDFLab
Up to this point you just have a bunch of jpeg files in a folder somewhere. Since this is not very convenient when you browse notes, I wanted to convert every group to a single PDF-file. When doing my research I found a very handy software called PDFLab. The software is a freeware and works really well.
Download PDFLab and fire it up. Now go to the folder where you saved all those jpeg files. Select them all, and drag them to PDFLab. This might take a couple of minutes, depending on your hardware.
When the files are imported into PDFLab, sort them by name by clicking ‘Name’. Now look through the list. If you have file names that go above 100 (‘bus-law_0_0100.jpg’), the sorting might not be done properly, since the file ‘bus-law_0_0103,jpg’ is sorted before ‘bus-law_0_013.jpg’. If you experience this, you need to move around the files manually until they are in the proper sequence.
When you’re happy with the sorting, hit ‘Create PDF,’ and enter an output file-name in the dialog which appears. If the PDF was generated without any errors, you’re all set.
 If you get an error message when generating the PDF, just hit OK, and try to create it again. If this doesn’t work, try to restart the software.
If you get an error message when generating the PDF, just hit OK, and try to create it again. If this doesn’t work, try to restart the software.
5. Delete/Backup the image-files
When you’ve made sure that your PDF is working fine, you can either delete you jpeg files or burn them to a CD just to be safe.
That’s it. You can now throw away all those papers into the recycle bin. The best thing is that you’re never more than a couple of clicks away from your documents.

Empty binders
6. Drawbacks
This solution is not perfect, but it’s sure better than having all those binders in the bookshelf or in a box somewhere. The main drawback of this is that the documents are not searchable. This could possibly be solved with OCR, but according to my experience, OCR is still not powerful enough to recognize all handwriting. OCR also tend to mess up documents which mix text and images. However, if I was able to scan these documents into a PDF with OCR recognition, this would be the optimal solution, since it would both be searchable and consume less space.






Some people do definately have toooooo much time….
I find that spotlight does a pretty good job at finding content within PDF’s so it would be searchable to some extent, and with a little organization of the documents into relevant folders I would expect it to be quicker to find than in a paper based system.
Tristan,
Ehh, no, I really don’t have that much time. But since the scanner got ADF, the only thing you need to do is to re-stack the feeder once in a while. Therefore while the scanner is working.
Jacob,
But since these are just images, they won’t be searchable. Unfortunately, this is one of the drawbacks of this solution.
I use Knox and Yep to organize all my pdf’s. Yep has a great interface for tagging and viewing pdf’s. Knox help keep them secure. I got the inspiration here. I used a Xerox scanner at work to do the initial work, and have a small USB powered Canon scanner for the few new documents I need to keep. My employeer started sending out payslips as pdf’s by email, so there is hardly anything but receipts I need to scan now.
To get round the OCR issue many PDF creation apps let you add tags & keywords to up your search options.
Aidian,
That’s a good idea. Never thought of that. However, it doesn’t completely solve the OCR problem.
I’ve been using Combine PDFs, to achieve that same thing. It is also a freeware mac application and performs the same basic tasks as PDFLab.
I also use Yep to organize my PDF documents. It used to be freeware, but as of v1.2 it is now $34. It is a great app and is very useful. Check it out.
Viktor:
I was trying to do the same thing just this week.
My scanner doesn’t have an ADF so I used one at my university; it’s almost the exact same model as yours.
I wondered if you’d had feeding problems with A5 documents (half-legal size for US readers) with your HP scanner? Sometimes it just pulls them in skewed, and when I try to intervene, it usually results in a paper jam.
Thanks,
Matt :-)
Matt,
I never tried A5, but I wouldn’t be surprised if it does, because I had a couple of US Legal papers that was cut in half, and those often got stuck. My experience is that these papers often work fine as long as you don’t do a double sided scan. However, smaller than half US Legal tend to get stuck even if you only scan one side.
And you’re right about the skew part too, many papers, not only smaller ones, got a bit skewed. In particular if the stack you loaded the scanner with is mixed format.
Anyone aware of any WINXP equivalents of the various software mentioned above?
I really suggest the Fujitsu ScanSnap for this. I read a comment that noted they had some paper size problems. The utility with the scansnap installation auto detects paper size and color. You can reduce the quality down to about 75 dpi and it really cuts the file size down. And finally, it is really really fast. It really flys. The only draw back is that it uses a gravity feeder which is less than great because there is a jam potential. Genearlly speaking.. as long as you are there to fix the jams when they happen it is really not a big deal. The paper never gets eaten.
Great, now you have hundreds (thousands?) of files that you’ll never look at instead of dozens of binders. Just bite the bullet and chuck it all — you won’t miss *any* of it.
Actually, this is pretty handy for researchers when combined with a data-organizing software like Endnote. When I was working on my thesis, I entered each book or article’s bibliographic info into Endnote, along with tags and a summary. It also had a “link-to” option for both external websites and internal documents, so I scanned anything I could, saved it in a special Windows Explorer folder, and linked each article’s bibliographic info to the article itself. Endnote used the information to do all the footnoting and bibliography pages for me, and if I was challenged on anything by my adviser I could go back to the source really easily.
Masale,
Check at lifehacker. They wrote about some win-xp program in the article where they featured this article.
kurt,
I have no experience with that scanner, but the paper problem is not a huge problem. The scanner I was using also detect paper size, color etc. without any problems. It did jam a couple of times, but I think all scanners (at least in that price-range) would when you mix paper sizes and type.
As for the quality. I chose 150DPI because I want to make sure that the notes will be readable. I did some experiments with 75DPI but found the quality to be insufficient. With 150DPI and JPEG with the ‘higher’ option (equivalent to ~7-8?), each page takes between 100-700 Kb in 16 bit color. Interestingly enough I found that grayscale images took up more space than the color ones.
CClio333,
I did a quite similar implementation a while back for a company. They wanted to get rid of several binders of old medical files. Since these files were only occasionally used, it didn’t make any sense to type in all the information into a software. Instead I set up Gallery and had them scanning in documents and uploading them to Gallery with an identification tag (like SS). Buy doing this, they could easily search the gallery for a patient, and get all the related documents.
anyone know of a decent OSX-compatible scanner with a document feeder besides the Snapscan? I’m sure it’s nice but I just want something to use once (over a weekend or two of course) to capture all my papers. ideally it would support 1-bit 300/600ppi TIFF format (because scanning printed docs as continuous tones gives you craptastic quality and wastes space).
I did the same thing, and it has worked well. Each binder goes into it’s own folder, and just like before I have to search to find something. Before I had to choose a binder and flip through paper pages. Now I choose a folder and flip through images.
42,
The HP ScanJet 5590 is a decent scanner that works quite well with OS X. The hardware is great, but the software is not the best piece of software ever written for OS X (I’m suspecting that someone from Microsoft was involved with the development of the software…=).
For OCR and archiving, I use DevonThinkPro Office, a very powerful database application for mac with built-in OCR. It can also import non-searchable PDFs and convert them to searchable
If scanning software is the issue, a few post above mentioned Yep. You can scan directly into Yep and combine the files at the same time. Really handy!
btw — does anyone know of a service that does scanning. I myself, don’t have the time to do it — but I would through money at it.
Mark,
Interesting. I’ll check that out.
Dara,
I’ll check that out too.
As for a scanning service – I think I’ve heard about some company doing that. However, I cannot recall any names.
Viktor,
Your link to Gallery didn’t work.
CClio333,
You’re right! My bad. I updated it and It should work now.
If you don’t want to scroll up, the right address is gallery.menalto.com.
Thanks for letting me know.
I do something similar to this.
I have a HP Laserjet 3030. It has a ADF and can scan something like 10-12 pages (single-sided that is) per minute.
The nicest feature is that when I put a document in the ADF, the HP Scan software pops up in OS X ready to “scan all” and save directly to a PDF.
I use QuickSilver instead of Yep, the Finder, Spotlight, to find my scanned documents.
I just use a simple naming convention for files. I create folders for logical groups like “taxes”, “school”, “bills” and folders therein.
Each document is named using YEAR-TAG-TAG-TAG-…-TAG.pdf (e.g. taxes/2005-federal-taxes.pdf).
No, this doesn’t address the OCR problem but I’m not saving tons of text at the moment, mostly financial documents, bills, etc. I usually type my course notes during class using my laptop anyway… heh.
Hmmm I did just AI and Computer Vision courses. Maybe I have a summer project: write software that does this entire process from the ground up. :-)
Brian,
Interesting idea. The main reason why I chose not to use PDF-output thought was due to the file size. If I instead went with a JPEG and then converted to PDF with PDFLab, I cut the file-size in half,while quality stayed the same.
If you do go a head and write you software, please let me know how it worked out.
adobe acrobats ocr is a great thing. on the screen you see the scanned pages perfectly readable and in the backgroud there is the ocr processed text. so the docs get searchable but remain readable and don’t get messed up. of course there’ll be errors in the ocr, so the search might not find everything but that’s better than a nonsearchable paper file.